
How to train Chat GPT with your own Data
What is Chat GPT? By today I am sure you already know what Chat GPT is, and I will not bore you with what you already know about Chat GPT. Instead, I will show you how to train Chat GPT with your own data, specifically PDF files, with a little help from the Langchain framework.
What’s In It For You?
- Choices: Learn how to use Chat GPT with your PDF documents
- Sources: Discover how Chat GPT can answer questions, including the source where it found the information.
- Alternatives: Discover other ways to train Chat GPT on your own documents.

Is this guide only for developers? No, it is not, it certainly helps if you have some Python knowledge, but you can follow along as a non-coder. Or you test it with the complete Colab Notebook I share in this guide.
How to train Chat GPT with your own Data, but why?
Good question. Several answers come to my mind.
- A more personalized model
- Data I care about
- Possibility to get knowledge out of my own data, which was not possible before
- AND data after September 2021
As an AI model developed by OpenAI, my training only includes data up until September 2021.
There aren’t many things like this answer that internally make me go…

That’s why I will show you step by step how you can start querying your pdf files using Chat GPT in under an hour.
Requirements
Here is what you will need for this how-to guide.
- A Google account
- An OpenAI account
- A credit card
Wait, what? I need a credit card? I am out of here. No, it’s not a crazy expensive amount that needs to be paid. I spent 20 cents for this tutorial to work. So if 20 cents is too much, this is the end of this tutorial. No, seriously, I hope you are still here with me.
What do I pay for?
You might be lucky (I wasn’t) and get some free credits to test the OpenAI API.
Why is this not for free? Well, creating small chunks out of your data and storing them in a format optimized for Chat GPT is not free. And asking questions and getting answers upon your data is also not free of charge.
Preparation
Let’s start with the Google Account. If you already have one, great move to the next step. If not, create a Google Account; it is free. With your Google account, you can access Google Colab and Google Drive; both tools are free.
Next Openai, as mentioned previously, we need an Openai API Key to access the Embedding and Chat functionality of Openai. If you already have an account, you should create a new API Key, and if you don’t have an account yet, sign up with Openai and go to your account settings to create a key.
Installation of the Requirements
Here is the Link to the complete Google Colab Notebook; make a copy in your Drive (as shown below) and test it.

If you want to follow the single steps start a new Colab Notebook.
!pip install langchain
!pip install unstructured
!pip install openai
!pip install chromadb
!pip install Cython
!pip install tiktokenImport the Langchain Packages
Langchain will help you load the PDFs and also with the creation of the Index.
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.indexes import VectorstoreIndexCreatorOpenai
Next, you need to set the Openai API Key so that the content of your PDF files can be converted into embedding vectors representing your texts, which can be searched faster than normal text.
And also, for the chat interactions, you need the Openai Key.
import os
os.environ["OPENAI_API_KEY"] = "YOUR-OPENAI-API-KEY"Connect your Google Drive
Google might have asked you already for this after you created a copy of the Colab Notebook. If not, now is the time to give Google Drive permission to connect with this Notebook.
I didn’t rename my Drive or the Colab Folder; these are all the standard names provided by Google Drive and Google Colab. If you did rename your Drive, you have to adjust the folder path of the root_dir.
from google.colab import drive
drive.mount('/content/drive/', force_remount=True)
root_dir = "/content/drive/My Drive/Colab Notebooks"Path to your PDF files
Next, you need to create a folder where you want this Script to retrieve the PDF files from. Inside your Google Drive, where your Colab Notebook is create a folder with a name of your choice. I named my PDF folder data.
I uploaded the following files to my Google Drive, an “AI Index Report” with 24.5 MB and 300 plus pages, with many charts and graphs.
And a document called the “Code of Obligations”. It covers the laws of contracts and obligations in Switzerland with a size of 4.5 MB and 500 plus pages. The American equivalent would be the Uniform Commercial Code (UCC).
Create a variable for the pdf folder path and append the newly created folder to the root directory of your project. Finally, you try to get all files from the folder path using os.listdir().
pdf_folder_path = f'{root_dir}/data/'
os.listdir(pdf_folder_path)Loading your PDF files
It’s time to create a list of all contents of your PDF files.
To create the list, you iterate over every file fn in the given folder pdf_folder_path and then create a new path with the pdf_folder_path and the file name fn, to create a new UnstructuredPDFLoader object.
loaders = [
UnstructuredPDFLoader(os.path.join(pdf_folder_path, fn))
for fn in os.listdir(pdf_folder_path)
]Creation of the Vectorstore Index
Chroma is used as a vectorstore to index and search the embeddings. This process might take a couple of minutes based on the number and size of the PDFs that you uploaded to your Google Drive folder.
When using the VectorstoreIndexCreator, three things happen:
- Splitting documents into chunks
- Creating embeddings for each document
- Storing documents and embeddings in a vectorstore
index = VectorstoreIndexCreator().from_loaders(loaders)Let’s start chatting
It’s time to start to chat with the language model and check if it is aware of the content we embedded. With the command index.query() or index.query_with_sources() you can ask questions.
I reviewed the AI report and looked for information Chat GPT could not know. And I found a statistic about job postings and specialized skills compared between 2022 and 2012-2012 in the US.
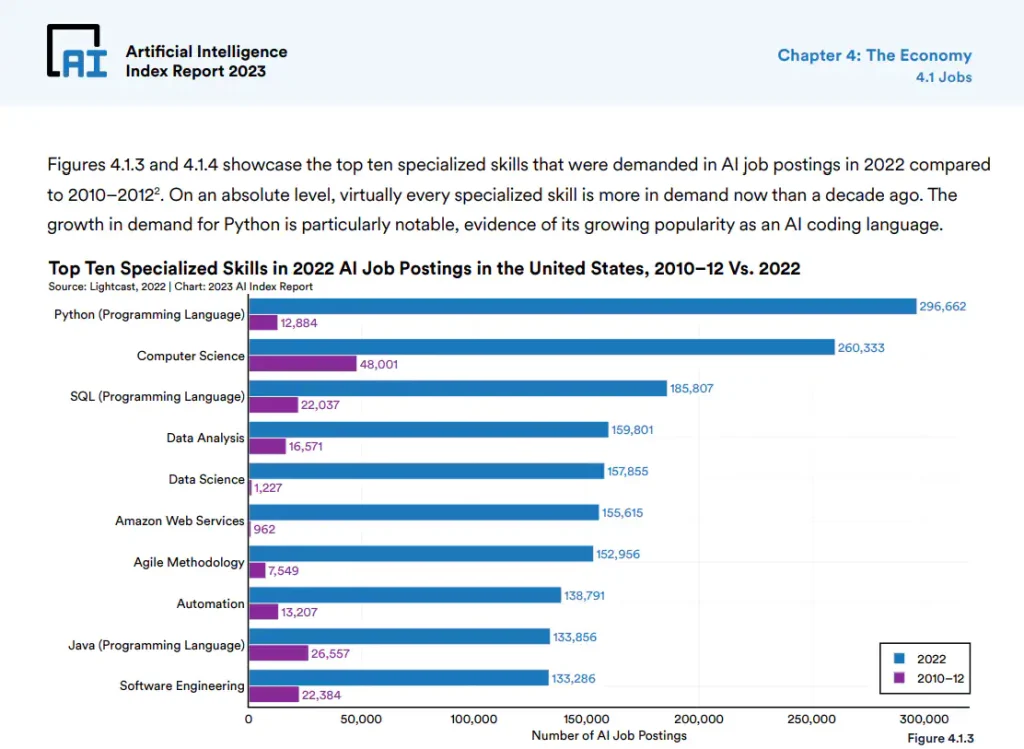
Here is the command I used to ask about the job postings.
index.query_with_sources("""
Which 3 specialized skills were found in job postings in the US in 2022
and what's the difference in demand compared to 2010-2012?
""")When we ask Chat GPT what it knows about it, we get the following result:

I hope you haven’t forgotten my inner reaction to the answer: As an AI model… September 2021…
Now, when we ask the same question to Chat GPT, who has access to our files, we get the following result:
{
'question': (
"Which 3 specialized skills were found in job postings "
"in the US in 2022 and what's the difference in demand "
"compared to 2010-2012?"
),
'answer': (
"The top 3 specialized skills found in job postings in the US "
"in 2022 were Python (Programming Language), Computer Science, "
"and SQL (Programming Language). The demand for these skills "
"increased by 592%, 63%, and 153% respectively compared to 2010-2012.\n"
),
'sources': '/content/drive/My Drive/Colab Notebooks/data/AI-Index-Report_2023.pdf'
}
NICE, that’s what I am talking about. This is the benefit of Chat GPT with embeddings.
Heads Up! Possible Changes in LangChain
Based on the newest documentation of langchain, the VectorstoreIndexCreator function can still be used for the time being since it is still present in the API. It is recommended, though, to take the manual step instead of this all-in-one wrapper. As it might not be maintained anymore in the future.
So, what are the benefits of the manual and more modular approach? Well, it gives you more control because you can choose the chunk size of the documents, the embedding model, the vector database, and the chat model if you want to use something other than Openai’s Chat GPT.
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
loader = TextLoader('documents.txt')
splitter = CharacterTextSplitter(chunk_size=1000)
embedder = OpenAIEmbeddings()
docs = loader.load()
chunks = splitter.split_documents(docs)
embeddings = embedder.embed_documents(chunks)
db = Chroma.from_documents(chunks, embeddings)
retriever = db.as_retriever()
qa_chain = RetrievalQA(llm=OpenAI(), retriever=retriever)
qa_chain.run("What does the document say about topic X?")Other Resources
Here are a few fellow content creators who produce great content about LLM that I can recommend if you want to hear other opinions about artificial intelligence.
- Matthew Berman, thank you for all the different Models you are testing.
- Nick, for his entertaining coding challenges
FAQs

Conclusion
Alright, Chat GPT with sources and answer questions about your data. All set up in a couple of minutes. Some readers might hope for a solution that respects all privacy aspects without making your files available to Openai to train their models. I will cover that in a future article.
What’s next? You can check if you have all the necessary knowledge to start training your own chatbot or how you can improve your prompting skills.
Thank you so much for your time and interest in this how-to guide. I understand that integrating AI into your processes can be complex, and you may encounter challenges or have questions along the way. Please don’t hesitate to reach out. I’d be more than happy to collaborate with you. See you soon.
Graz is a tech enthusiast with over 15 years of experience in the software industry, specializing in AI and software. With roles ranging from Coder to Product Manager, Graz has honed his skills in making complex concepts easy to understand. Graz shares his insights on AI trends and software reviews through his blog and social media.





